A Data-Driven Historical Analysis of Cosmo
Using NLP and image processing to analyze trends on Cosmopolitan Magazine covers
Magazine covers have an underrated influence on our culture. Even if you don’t read tabloids or women’s magazines, you can picture a Cosmo or People magazine cover and can give examples of the types of stories they run. Every time you’ve purchased groceries or gotten a snack for the plane, you see these magazines and they make an impression. And as you wait in line and read the sensationalized headlines maybe, every once in a while, in a weak moment, you even purchase one (just me? Okay).
To try to further understand magazines’–specifically women’s magazines’–market appeal and impact as cultural influencers, I decided to use data analytical tools to abstract their content strategy and marketing techniques. I extracted the text from magazine covers, performed NLP topic modeling, and used image processing techniques to understand graphic trends and representation. I wanted to analyze how their intention to appeal to women migrated from this:

to this:

I entered into this investigation with a few big questions about methodology. First, does this data source exist? I wasn’t sure if anyone had digitally assembled all the covers of any women’s magazine. Luckily, the academics had me covered. There is a Proquest database called the Women’s Magazine Archive that has covers of various magazines, including Cosmo from 1925-2005. That explains how I landed on this specific publication. I ended up using covers from 1950-2005 from this database and individually searching for and downloading covers for 2006-2019.
My second question was “can I use computer vision techniques to record text off of the .jpg files?” This had a more complicated answer:
I used Google’s tesseract optical character recognition (OCR) engine, an open source tool trained to recognize and extract text. Tesseract worked well on covers up until the 90s, with a single background color and text color, because the process uses binarization, bringing the pixel values above a threshold to white, and below to black.

Later covers with more sophisticated graphics meant tesseract ocr’s default process lost more than half the text. To solve this, I inverted the images and changed the binarization threshold to be between the background color and the lighter text colors and so was able to extract a larger percentage of the text.

However, I used a standard pixel value for all covers as the binarization threshold, I think that this would have a higher retention rate with a dynamic threshold that varied based on the background and text colors, a space for further work.
My last question was “what information can I extract using data science processing techniques that go beyond what I can generalize just looking at some example covers?” Leveraging natural language processing, clustering algorithms, and composite images, the answer was, “Quite a lot!”
With the recorded cover text, I performed natural language processing. Using NMF topic modeling, I saw these 6 topics over the 70 years of covers:
| Topic Name | Most Common Words |
|---|---|
| Sex: | make ways life sexy ever good bed hot know tricks things secret guys never feel |
| Mysteries: | complete mystery murder husband see stories girls short money summer suspense children special |
| Fiction: | best girl plus short stories girls story fiction life seller book diet two lover woman |
| Resolutions: | astrologer bedside money career guide cosmos health bonus star year plus beauty travel advice family |
| Relationships/Life: | life super way rich much affair know want quiz long relationship young |
| Miscellaneous: | first excerpt big girl together lovers making stunning turn marriage sexual girls romance |
Surprisingly, two out of six topics were associated with literature: fiction and mysteries, which seemed like a large percentage, based on my perception of Cosmo in my lifetime. However, I learned that the magazine serialized novels and short stories up into the 50s, and fiction continued to appear into the 90s.

As you can see on the graph below, which is of the percent of words on the cover in each topic averaged per year, the literature topics continuously decreased during the time period of covers I analyzed.
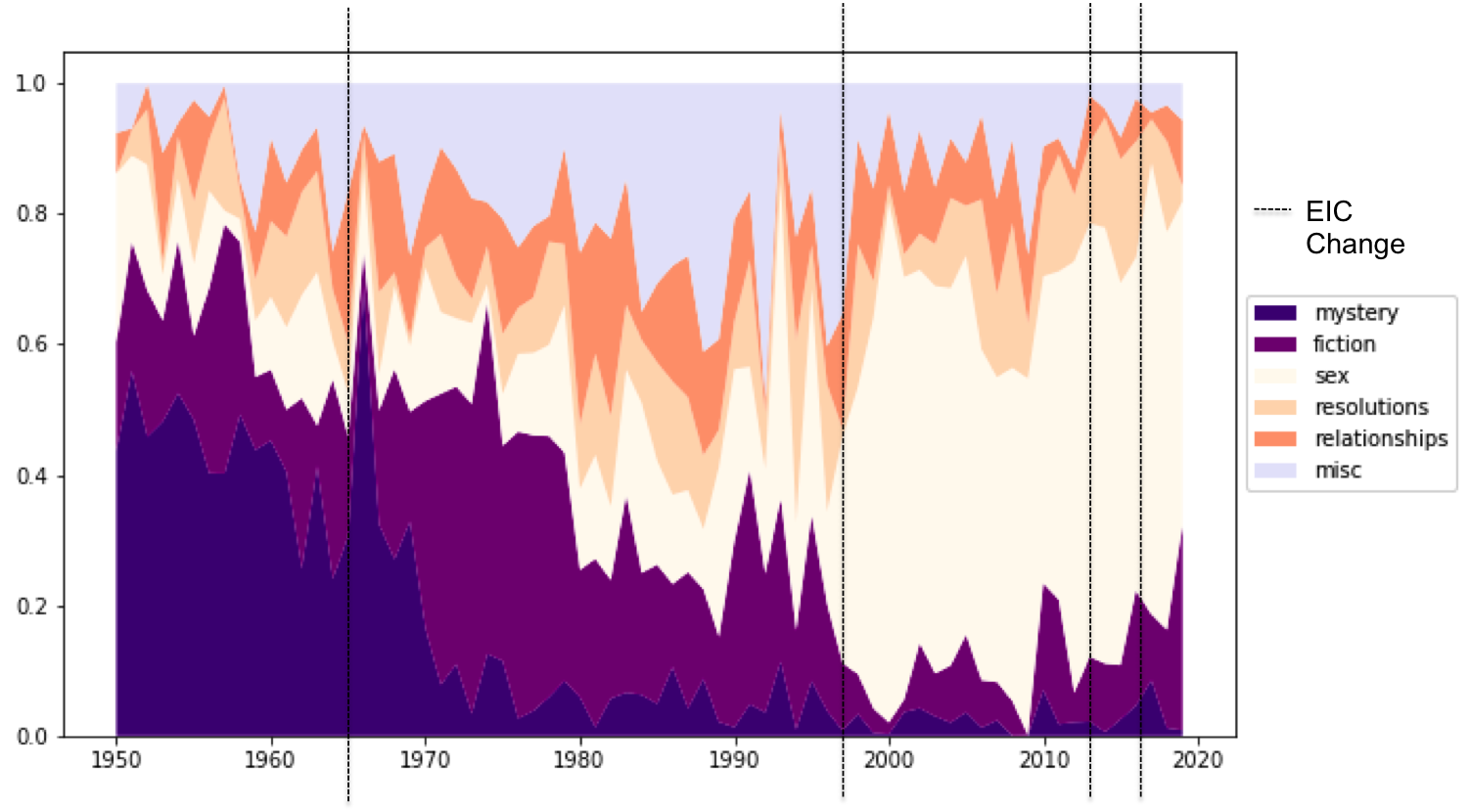
The vertical lines here denote changes in editors. Clearly, topics covered change when editors change. With the first female editor in 1965, Helen Gurley Brown, there is a decrease in literary topics, and in turn you get more about women’s individual lives. When Brown’s 20-year tenure ended. the shift away from literary content stepped up again to an extremely high percentage of words in the “sex” topic.
To understand more about these topics after the era of literature publication, I performed NMF on the text from 1980-2018 and found these topics.
| Topic Name | Most Common Words |
|---|---|
| Sex: | hot bed sexy guys never things moves guy really naughty |
| Astrology: | astrologer bedside cosmos health career guide astral bonus money star |
| Relationships: | man woman girl husbands tantalizing makeup married friends woman secrets marriage |
| Cover Girl: | money big me work hollywood quiz hot good sexy young |
| Secrets: | bad know secrets surprising couples reveal boyfriend terrace readers believe |
| Miscellaneous: | read things movie keep beautiful working fast bitchy husbands discover |
| Hints/How-to: | guide interested girls know everything relationships christmas marriage survival |
| Power: | best ahead getting scary power years sexy turning learn loving |
| Human Interest: | happen know girl help even rape living sure perhaps stories someone |
| Health/Beauty: | feel tricks secret take story diet stay skin sexier fearless tips beauty |
If we look at a percentage of words in each of these topics on covers we can see that the 2000s showed a decrease in the “Relationships” topic reflecting a societal shift away from defining women via boyfriends and marriage.
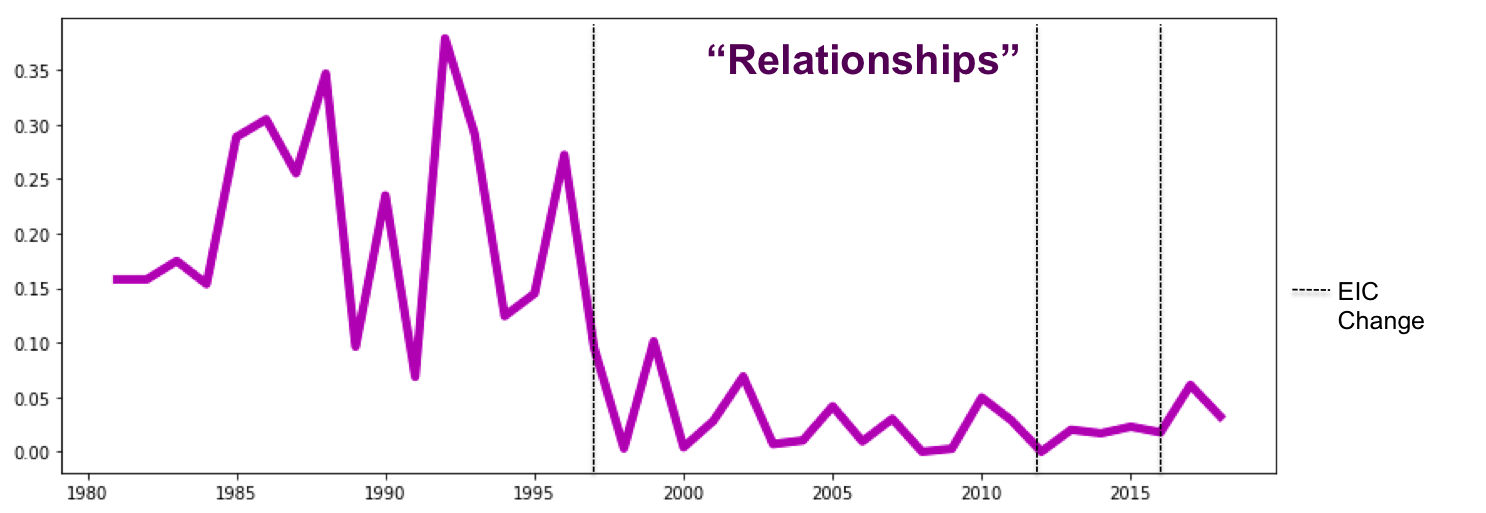
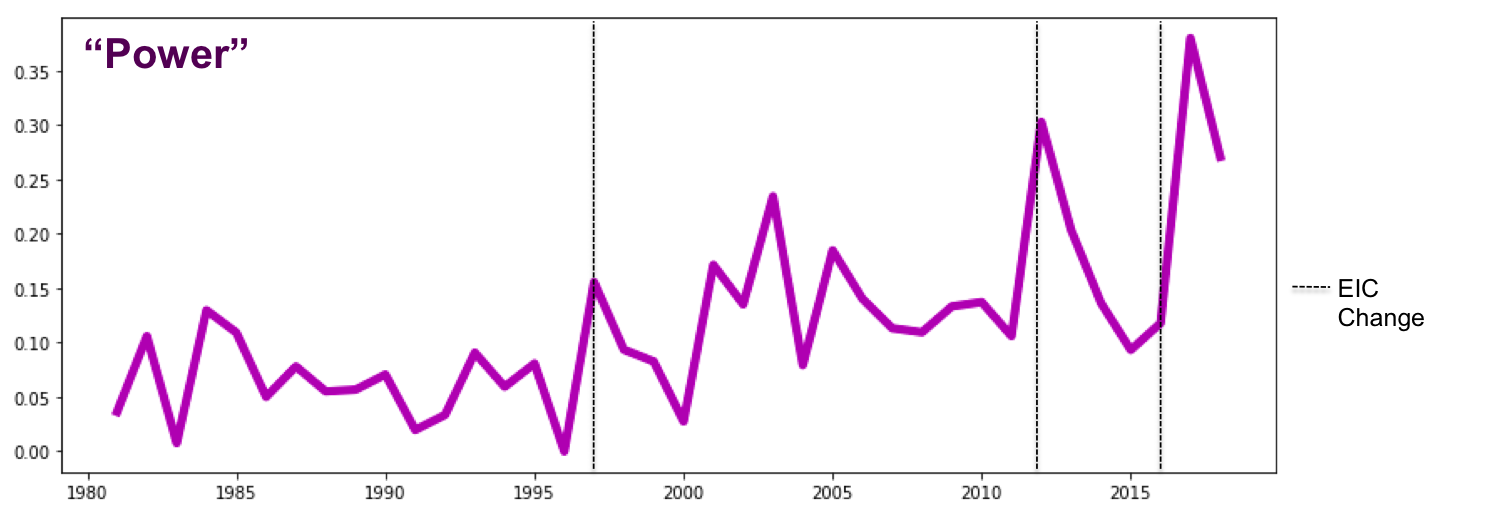
At the same time, the health/beauty and sex categories rose, and we also see an increase in the percentage of “power” words, indicating an editorial shift toward empowerment, away from condescending topics like “how-to guides.”
Finally, I also did image analysis to further support my textual analysis. Using average pixel images I created a composite cover for each decade, and the 50s and 60s did not have a cohesive style (see the 1962 and 1964 images) besides the ever-present Cosmo logo. However, when I divided the composite into before and after 1965, I found that I could see a portrait start to appear, shifting to a single “cover girl.” This further supports my findings that Cosmo’s content in the late 60s shifted to focus on the woman as an individual and her particular interests.

Then starting in the 70s we see the standard cover consisting of a central woman usually white posing with 3/4 of her body shown.

With the more contemporary topic changes to more empowering language, I am interested to see how much longer this style persists, because to me it feels a bit more objectifying than empowering, and out of curiosity I looked at the most recent covers at the time of this analysis:

These are March and April’s covers from this year (2019). In one, we have a pizza front and center, and the other is the first cover with multiple people since the 1960s. It does seem the mold is starting to break down.
In using data to understand text and graphic changes, I was able to answer my final question:
Are magazines like Cosmo merely a reflection of changes in attitudes towards women over time, or are they driving the changes in those attitudes?
The answer is likely both. We can see the changes in Cosmo’s topics correlate highly with the different waves of feminism, and, likely, the magazine played a part in making sexual empowerment mainstream. But if society were not already moving in that direction, then the magazines wouldn’t sell. I think that they want to be seen as pushing the boundaries and empowering women, but not to a level that is close to the most progressive feminist thinkers.
Overall, my research convinced me that we are continuing to see growth and changes in society’s acceptance and support for the autonomy and individuality of women, and that these changes are reflected in the commercial reading material that is meant to attract and portray us.

 ”
”